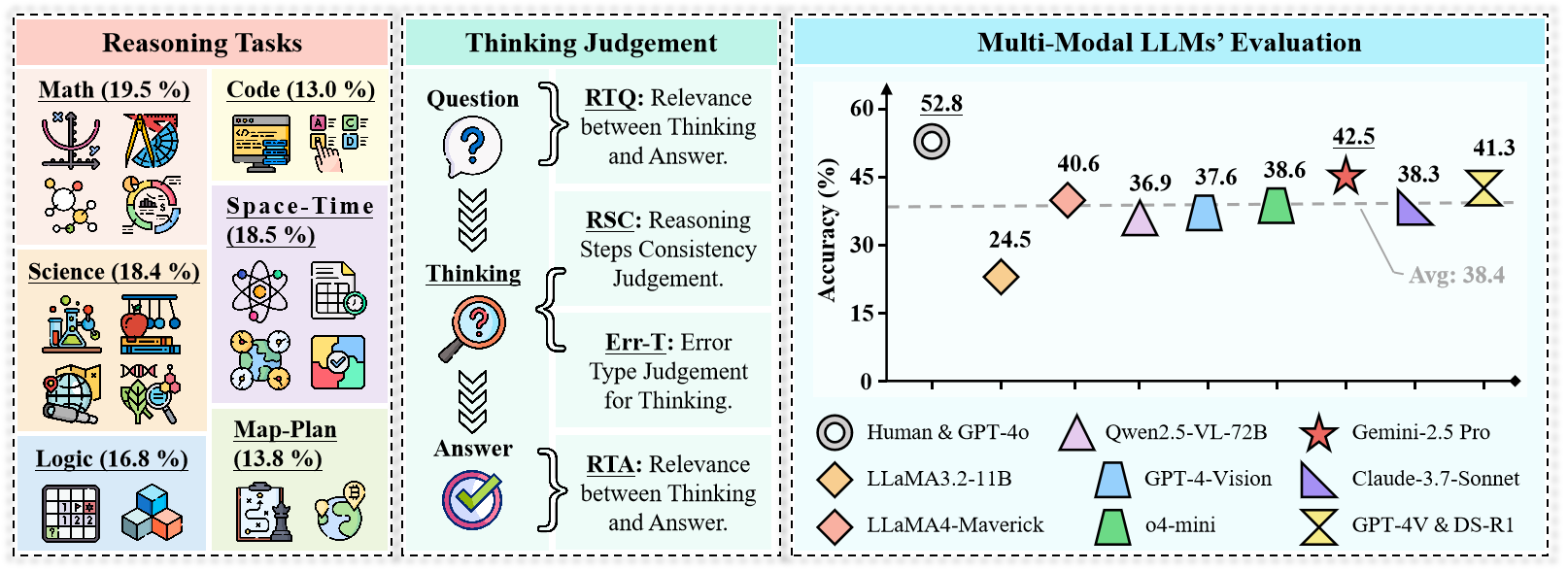
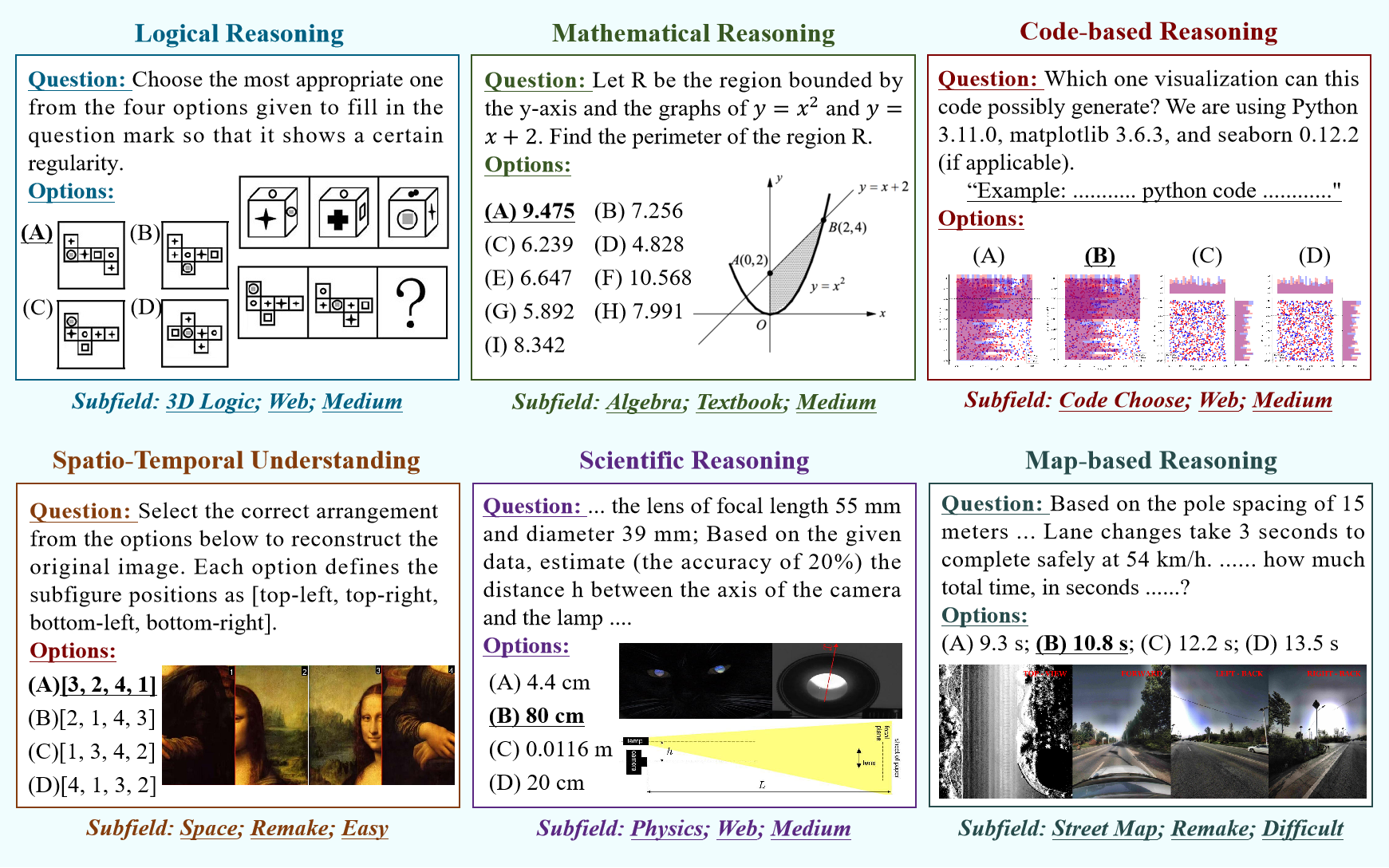
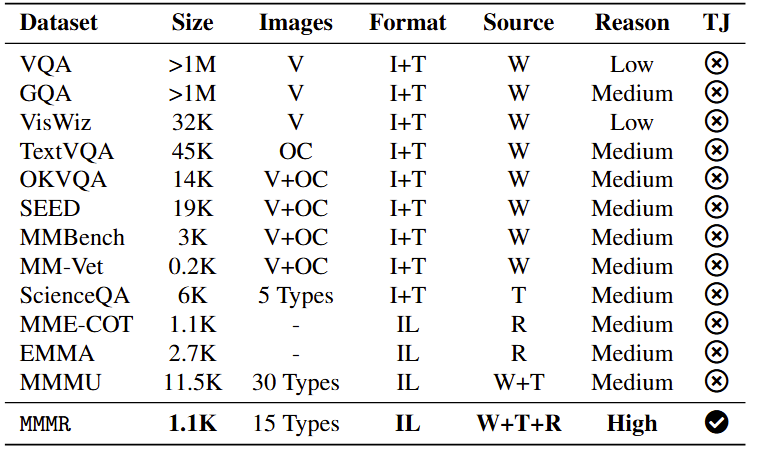
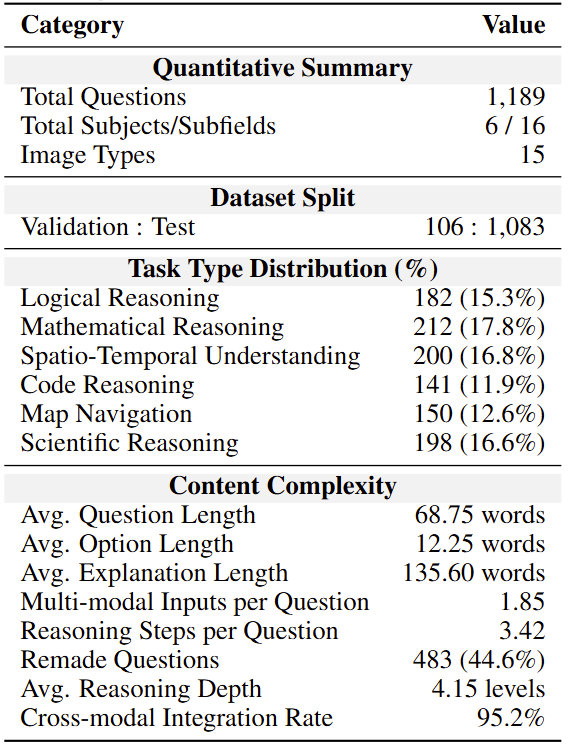
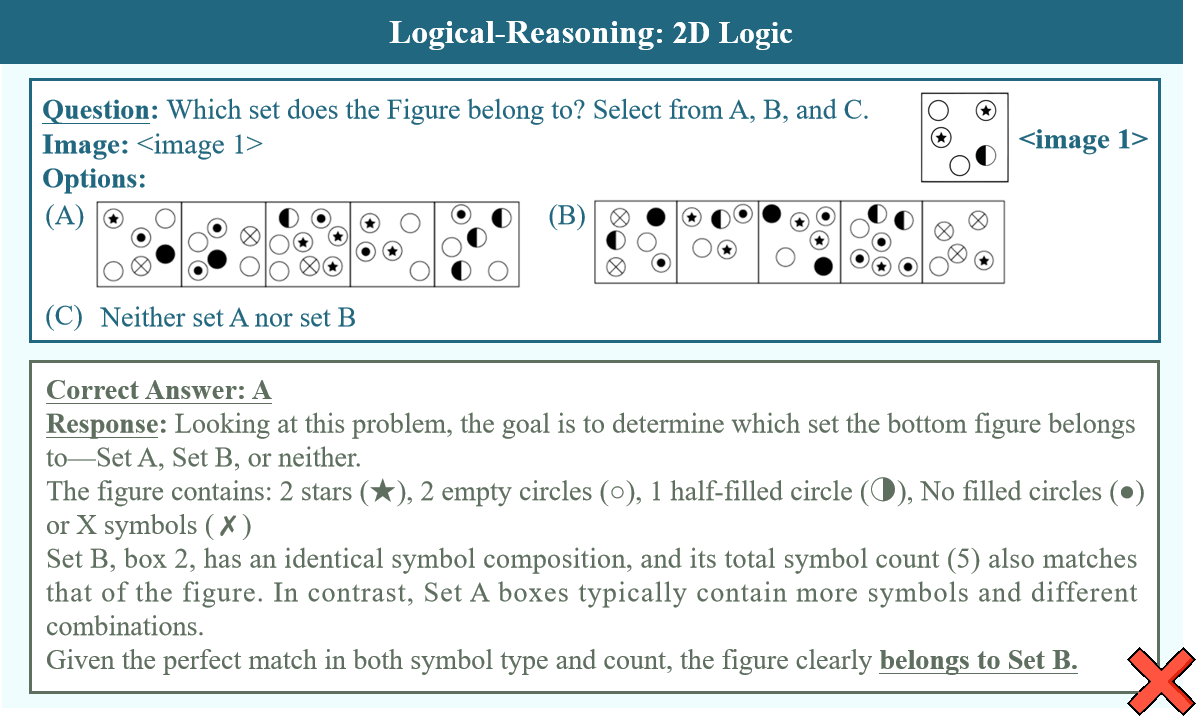
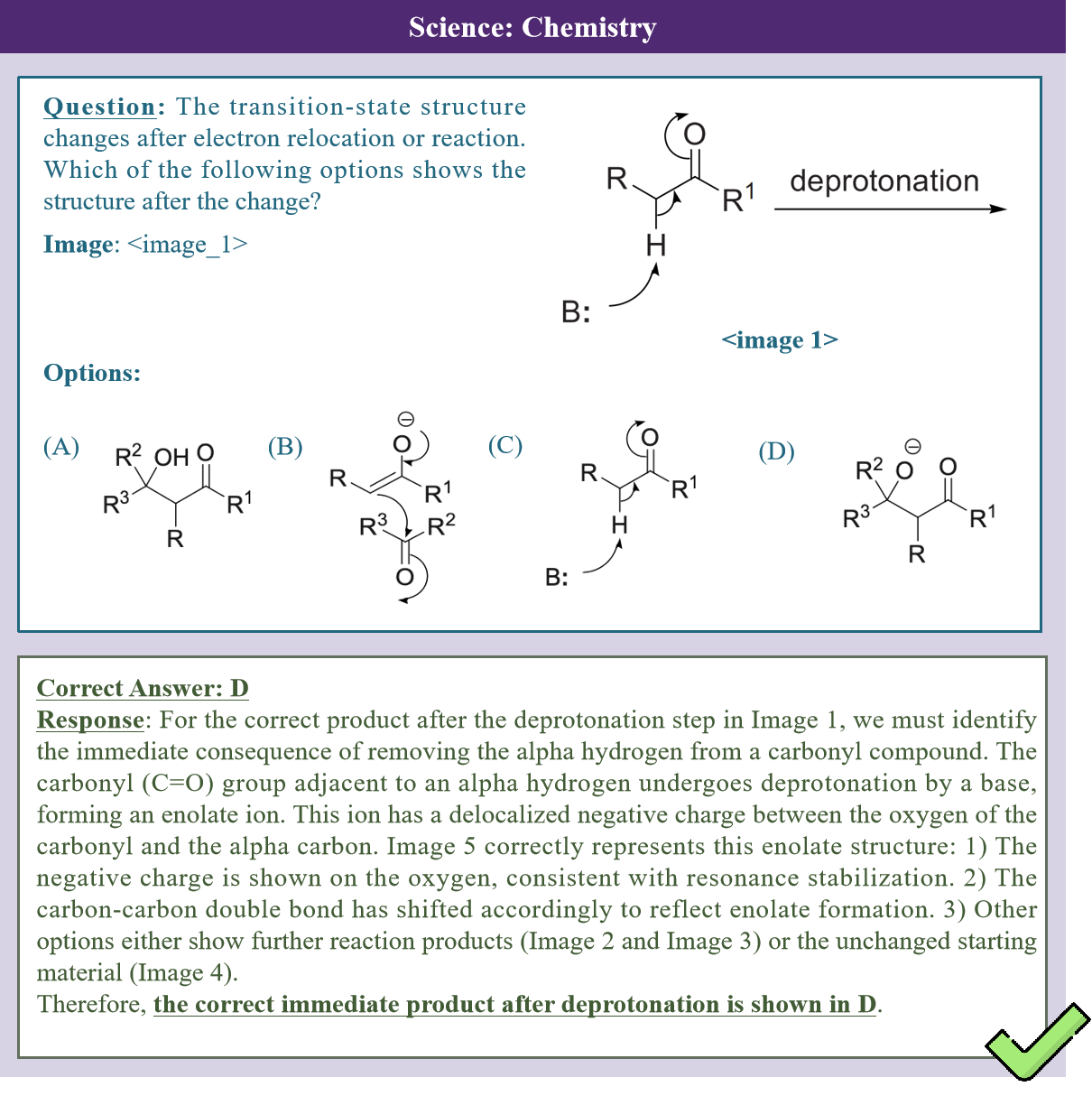
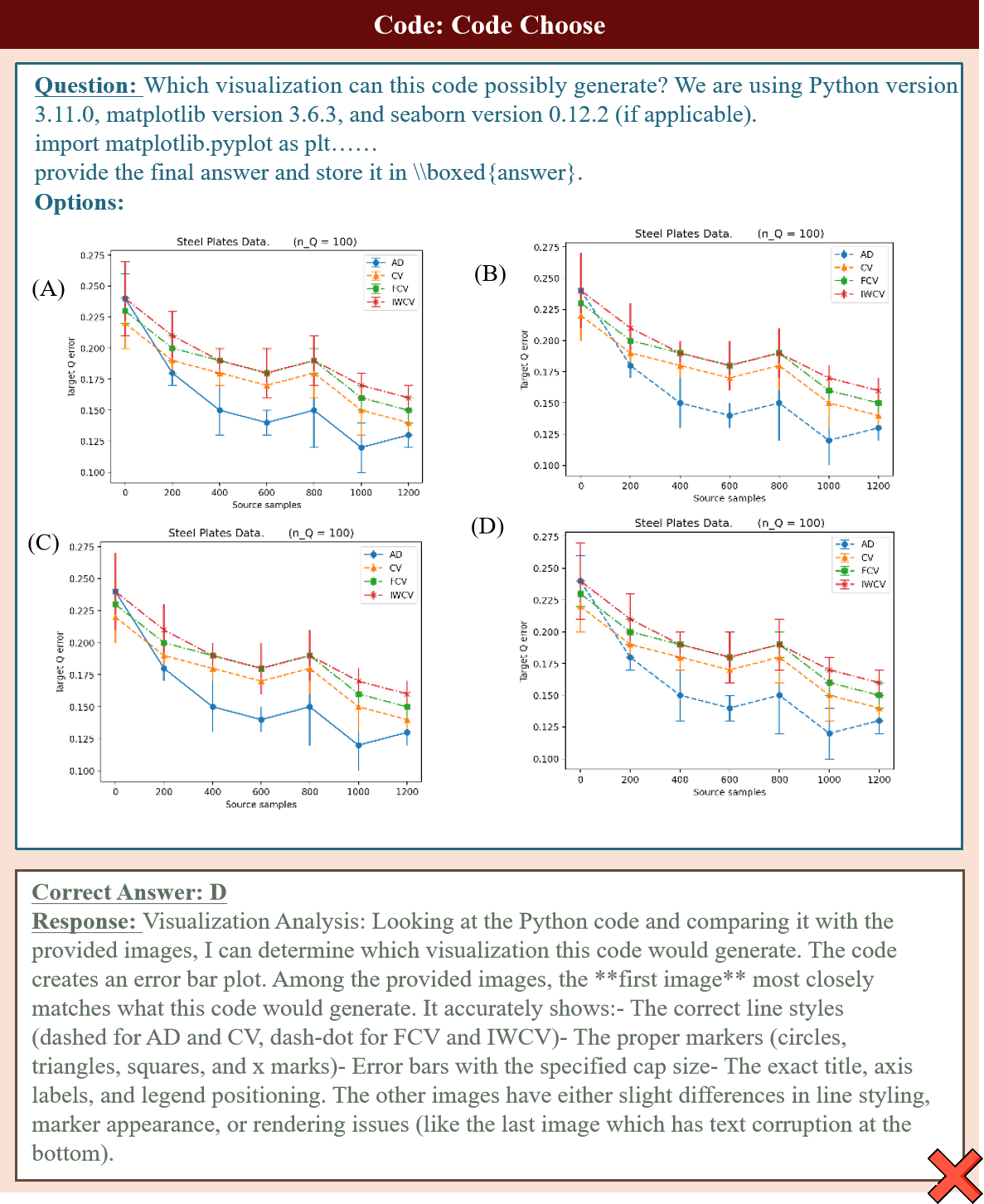
Recent advances in Multi-Modal Large Language Models (MLLMs) have enabled unified processing of language, vision, and structured inputs, opening the door to complex tasks such as logical deduction, spatial reasoning, and scientific analysis. Despite their promise, the reasoning capabilities of MLLMs—particularly those augmented with intermediate thinking traces (MLLMs-T)—remain poorly understood and lack standardized evaluation benchmarks. Existing work focuses primarily on perception or final answer correctness, offering limited insight into how models reason or fail across modalities. To address this gap, we introduce the MMMR, a new benchmark designed to rigorously evaluate multi-modal reasoning with explicit thinking. The MMMR comprises 1) a high-difficulty dataset of 1,083 questions spanning six diverse reasoning types with symbolic depth and multi-hop demands and 2) a modular Reasoning Trace Evaluation Pipeline (RTEP) for assessing reasoning quality beyond accuracy through metrics like relevance, consistency, and structured error annotations. Empirical results show that MLLMs-T overall outperform non-thinking counterparts, but even top models like Claude-3.7-Sonnet and Gemini-2.5 Pro suffer from reasoning pathologies such as inconsistency and overthinking. This benchmark reveals persistent gaps between accuracy and reasoning quality and provides an actionable evaluation pipeline for future model development. Overall, the MMMR offers a scalable foundation for evaluating, comparing, and improving the next generation of multi-modal reasoning systems.